The Hidden Cost of Your API Gateway: 8 Real Failures That Aren't on the Pricing Page
Most teams pick an API gateway the same way they pick a cloud region: whichever default the docs put in front of them. Then, eighteen months later, an outage, a surprise invoice, or a security incident exposes what they actually bought.
We dug through the last year of incident postmortems, threat reports, and developer write-ups to map the failure modes teams are actually hitting in production — and to show, concretely, what Crate does differently.
This isn’t a feature list. It’s a list of things that have already broken for other people.
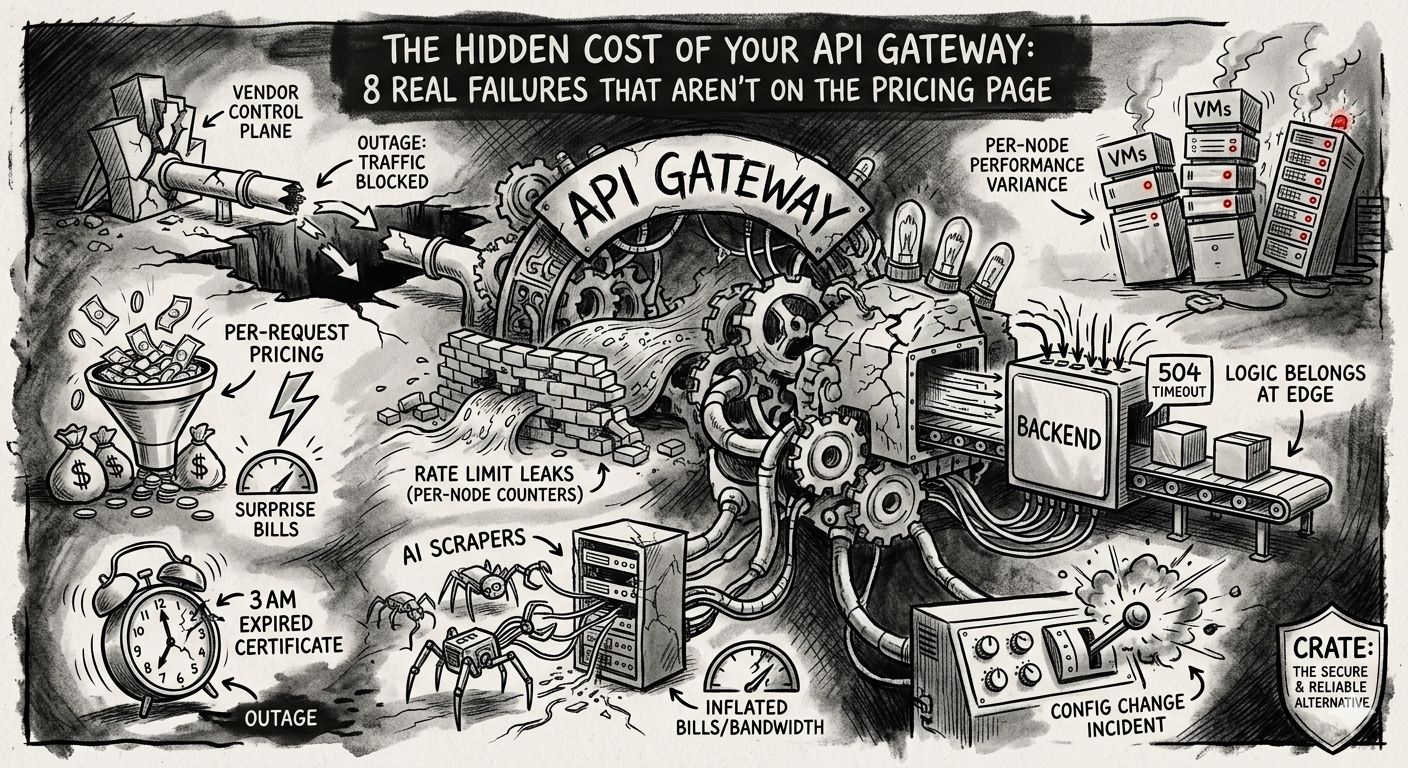
1. The control-plane outage that takes your traffic with it
Most managed gateways couple two things that shouldn’t be coupled: the data plane that serves your traffic, and the control plane that lets the vendor manage it. When the vendor’s dashboard goes down, your API goes with it.
It’s not a hypothetical:
- StatusGator, which has monitored Amazon API Gateway since 2015, logged a 12-hour-22-minute degradation warning on April 27, 2026 (source). In a recent 90-day window, AWS had five separate incidents with a median duration of 42 minutes (source).
- Industry write-ups describe the same chain reaction every time: “In extreme cases, the Gateway may completely fail, causing a chain reaction of service disruptions across your entire system” (Gravitee, Aug 2025).
Your SLA credit doesn’t refund the customers who churned during the outage.
How Crate is built differently: The Crate Gateway is stateless and fails open. Every node caches the routes, rules, and certificates it needs to run autonomously. If our control plane, dashboard, or billing API is offline, your traffic keeps flowing. That’s an architectural guarantee, not an SLA promise.
2. The four-figure (sometimes seven-figure) surprise bill
Per-request pricing on managed gateways punishes the architectures developers are told to build: serverless, event-driven, IoT, polling clients. Then a misconfiguration or a normal growth month turns into a billing incident.
Real cases:
- Geocodio wrote a public postmortem about a surprise $1,000 AWS bill from a missing VPC endpoint (The $1,000 AWS mistake). In that same post, they noted that Recall.ai discovered they were paying $1M annually in unexpected AWS WebSocket data processing fees (same source).
- On AWS API Gateway, you’re charged for requests even when the gateway rejects them with a 429 (AWS re:Post). You literally pay to defend yourself against abuse.
- FinOps vendors now treat AWS API Gateway cost spikes as a regular customer problem, noting that costs are driven by “request volume, retry behavior, traffic patterns, and growth over time — not by provisioned resources” (CloudZero, Jan 2026). Translation: success is taxed the same as abuse.
How Crate is built differently: Bandwidth-based tiers, not per-request pricing. Send 100 requests or 100 million — if they fit your tier, the price is the same. Overage is $0.01/GB with no throttling and no error pages for being successful. You can’t be billed for traffic the gateway blocked, and you can finally cap a serverless app’s worst-case spend before a runaway client invents one.
3. Rate limiting that doesn’t actually limit
Most gateways apply rate limits per node. That works on a whiteboard. In production with a cluster behind a load balancer, it leaks badly.
Engineering write-ups put numbers on it: a user with a limit of “10 requests per second” hitting a 5-node cluster can comfortably push 50 req/sec, because each node only sees 2 and waves them through. That’s a 5x leak, by design (Grokking the System Design).
The downstream consequences are real. RSAC documented a streaming-service outage where a recommendation API entered an infinite loop and “thousands of automated requests from client apps began to overwhelm the service.” The remediation lesson was explicit: “Put rate limiting at the gateway or service mesh level, so a single buggy client or malicious bot cannot take an organization’s service offline” (RSAC Conference, Jun 2025).
If your rate limiter only sort-of limits, it’s not a backend protection mechanism. It’s a comfort feature.
How Crate is built differently: Atomic Redis Lua check-and-increment scripts enforce limits globally across the cluster. If you set 1,000 req/sec, you get 1,000 req/sec — not “roughly that, multiplied by however many nodes are healthy right now.”
4. AI scrapers eating your bandwidth — and your bill
LLM training and retrieval bots are the new DDoS: they’re polite, persistent, and expensive. The data is staggering and recent:
- Fastly’s Q2 2025 Threat Insights Report: AI crawlers made up roughly 80% of all AI bot traffic observed mid-April through mid-July. Fetcher request volume exceeded 39,000 requests per minute in some cases, “putting pressure on unprotected origin infrastructure, consuming bandwidth, overwhelming servers, and mimicking the effects of DDoS attacks, even without malicious intent” (Fastly press release · The Register coverage).
- Kasada tracked over 120 million requests from AI scraper user agents in a single quarter, with OpenAI alone sending more than 56 million requests in June 2025. Their conclusion: “Scrapers trigger cloud auto-scaling, inflating bandwidth and infrastructure bills while draining performance” (Security Boulevard, Sep 2025).
- The Wikimedia Foundation reported a 50% increase in multimedia bandwidth since early 2024, almost entirely from AI scrapers — not human readers (VKTR).
- Imperva’s 2025 analysis pegged automated traffic at 51% of all web traffic in 2024 (Clutch.co, Oct 2025).
- Akamai’s 2025 report found a 300% surge in AI crawler traffic year-over-year (Web1776 summary).
On a per-request pricing model, every one of those requests is a line item.
How Crate is built differently: A per-domain AI Shield blocks LLM scrapers at the edge before they reach your origin or count against your bandwidth tier. You don’t pay to filter them, and your auto-scaler doesn’t get tricked into spinning up capacity for bots.
5. The 3 AM expired-certificate page
TLS is still one of the most reliable ways to cause an outage. API7 published a case study of a SaaS customer hitting intermittent 502s in production — traced to an expired TLS certificate on an upstream service that nobody noticed until the handshakes started failing (API7, May 2025).
Worse, gateway misconfiguration around auth and TLS has caused real breaches. RSAC documented a fintech case where “a configuration change disabled strict signature checking on the API gateway (an accident during a library upgrade),” and attackers exfiltrated thousands of dollars over a weekend before anyone realized JWTs weren’t being validated (RSAC Conference).
Certbot cron jobs, manual rotations, and “we’ll write a runbook for it” are all places this fails.
How Crate is built differently: A custom ACME flow with Let’s Encrypt. The gateway intercepts /.well-known/acme-challenge/ on port 80, tunnels challenges to the control plane, and broadcasts issued certificates to every node. Point a domain at Crate and you get a green lock in under 60 seconds. Renewals, strict TLS versions, and modern cipher suites are automatic.
6. Config changes that turn into incidents
Industry analysis of AWS API Gateway acknowledges that “misconfigurations in your API Gateway settings, such as incorrect routing rules, overly restrictive throttling limits, or issues with authentication and authorization, can lead to outages or unexpected behavior. Even a simple typo in your API definition can cause problems” (AWS API Gateway Outage guide, Feb 2026).
If every routing change requires a deploy, and every deploy can take production down, your team will under-change the gateway out of fear. Bad routes accumulate. Old plugins stay attached. Nobody touches it.
How Crate is built differently: Routing rules live in gateway RAM and update instantly via a Redis broadcast — no restarts, no dropped connections. Every change is versioned, exportable, and one click to roll back. Regressions become reversible instead of incidents, which means teams actually iterate on the gateway instead of treating it as legacy.
7. Logic that belongs at the edge, sitting in your backend
A lot of gateway timeouts aren’t really gateway problems — they’re backend problems caused by work that should never have reached the backend.
The 504 pattern is well-documented: “A 504 error occurs when the gateway does not receive a response from an upstream service within the configured time limit” — often because of slow auth checks, payload validation, or transforms happening behind a thin gateway instead of at it (Bobcares, Dec 2025 · LogicMonitor).
A real example: an engineer published a 2 AM postmortem about a video-processing API where “60% of requests failing with cryptic 504 errors” turned out to be sync work that should have been pushed to async queues at the gateway layer (Medium, Dec 2025).
How Crate is built differently: A plugin pipeline at the edge handles the work that doesn’t belong in your backend:
- JSONata request/response transforms
- CORS
- API key validation
- IP allow/deny
- Payload size limits
- Mock responses
Plugins can be authored, simulated, attached, and reordered on domains and rules without redeploying backends. That shortens the distance between “we need to change X” and “X is live.”
8. Per-node performance variance under load
When traffic spikes, stacked architectures (VMs inside orchestrators inside shared VPCs) show their seams. Industry writeups describe the same pattern: “With too many requests to handle, the gateway may start to slow down, leading to delayed responses… the API Gateway may hit its connection limits and fail to route requests to the backend services” (Gravitee).
That’s an architecture problem dressed up as a scaling problem.
How Crate is built differently: Compiled Go binaries running directly on bare metal with a zero-copy routing engine. Requests are inspected and forwarded without buffering entire bodies, which keeps the memory footprint low even under heavy file-transfer load. The result is sub-millisecond gateway overhead, predictable tail latency, and headroom that doesn’t evaporate under bursts.
The pattern
If you look at all eight failures together, the same shape keeps appearing:
| Failure mode | Root cause |
|---|---|
| Vendor outage = your outage | Coupled control + data plane |
| $1K (or $1M) surprise bill | Per-request pricing |
| Rate limits leak at scale | Per-node counters, no global state |
| AI bots inflate your bill | No edge filtering for LLM traffic |
| 3 AM cert expiry | Manual TLS lifecycle |
| Every change is a deploy | No hot-reload, no versioning |
| Gateway 504s | Logic in the wrong tier |
| Latency under burst | Stacked, buffered architecture |
None of these are exotic edge cases. They’re the default of how mainstream gateways are built and priced. They show up in postmortems every quarter.
The takeaway
If your current gateway is slow, costs scale with request count, or disappears when the vendor’s dashboard hiccups — that’s not the state of the art. That’s just what you’ve been paying for.
Crate is the version where:
- Performance is a hardware decision, not a pricing tier
- Reliability is architectural, not contractual
- Cost tracks bandwidth, not behavior
The failure modes other gateways treat as “edge cases for your ops team” are the ones we designed out of the product.
Sources
- StatusGator — Amazon API Gateway status history: https://statusgator.com/services/amazon-web-services/amazon-api-gateway
- IsDown — Amazon API Gateway outage tracker: https://isdown.app/status/aws/amazon-api-gateway
- Gravitee — What to Do When Your API Gateway Fails Under Traffic (Aug 2025): https://www.gravitee.io/blog/api-gateway-fails-under-traffic-what-to-do
- Geocodio — The $1,000 AWS mistake (Nov 2025): https://www.geocod.io/code-and-coordinates/2025-11-18-the-1000-aws-mistake/
- AWS re:Post — Pricing clarification for API Gateway: https://repost.aws/questions/QU5y4fo-e3RWyU5r4VmyPIzA/pricing-clarification-for-api-gateway
- CloudZero — AWS API Gateway Pricing Simplified: A 2026 Guide (Jan 2026): https://www.cloudzero.com/blog/aws-api-gateway-pricing/
- Grokking the System Design — Rate Limiter System Design: https://grokkingthesystemdesign.com/guides/rate-limiter-system-design/
- RSAC Conference — Three Outages That Changed How We Think About API Security (Jun 2025): https://www.rsaconference.com/library/blog/three-outages-that-changed-how-we-think-about-api-security
- Fastly — AI crawlers make up almost 80% of AI bot traffic (Aug 2025): https://www.fastly.com/press/press-releases/new-fastly-threat-research-reveals-ai-crawlers-make-up-almost-80-of-ai-bot
- The Register — Fastly warns AI bots can hit sites 39K times per minute (Aug 2025): https://www.theregister.com/2025/08/21/ai_crawler_traffic/
- Security Boulevard / Kasada — Q2 2025 Bot Attack Trends (Sep 2025): https://securityboulevard.com/2025/09/q2-2025-bot-attack-trends-ai-scraping-scalper-bots-and-travel-fraud/
- VKTR — The Internet Is Being Overrun by AI Bots (Oct 2025): https://www.vktr.com/ai-technology/the-internet-is-being-overrun-by-ai-bots-and-websites-are-paying-the-price/
- Clutch.co — Bot Traffic Is On the Rise (Oct 2025): https://clutch.co/resources/bot-traffic-rise-manage-bandwidth-strain
- Web1776 — AI Web Crawlers in 2025 (Feb 2026): https://www.web1776.com/2026/02/02/ai-web-crawlers-in-2025/
- API7 — Gateway Logs: Your Secret Weapon for Troubleshooting APIs (May 2025): https://api7.ai/blog/gateway-logs-for-troubleshooting-apis
- AWS API Gateway Outage guide (Feb 2026): https://ccgit.crown.edu/cyber-reels/aws-api-gateway-outage-what-happened-and-how-to-prepare-1764808146
- Bobcares — How to Fix 504 Gateway Timeout Error in API Gateway (Dec 2025): https://bobcares.com/blog/how-to-fix-504-gateway-timeout-error-in-api-gateway/
- LogicMonitor — API Gateway Timeout: Causes and Solutions: https://www.logicmonitor.com/deep-dive/api-monitoring-tools/api-gateway-timeout
- Medium / Arnab Golder — AWS API Gateway Timeout? Here’s How I Fixed It (Dec 2025): https://medium.com/@arnabgolder7/aws-api-gateway-timeout-heres-how-i-fixed-it-4d9875e197bc