The Orchestration Friction: The Reality of Building MCP Servers
Article 3: The Orchestration Friction — The Reality of Building MCP Servers
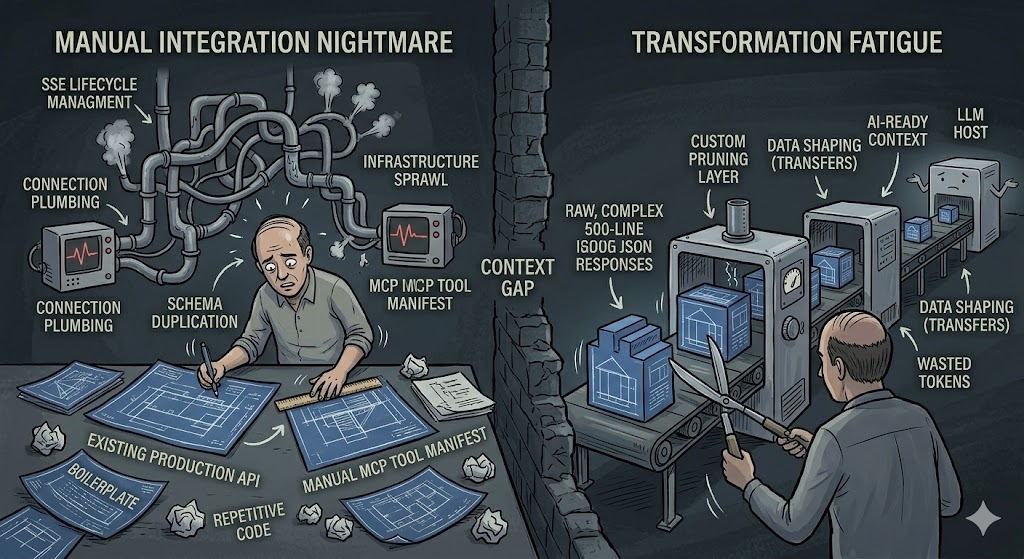
If you’ve followed the series so far, the theory makes sense: you want your data to be discoverable, and you want to use SSE for the transport. But when you actually sit down to build an MCP server in Go or JS, you quickly realize you’re spending most of your time re-describing things you’ve already built.
1. The Redundancy of Manual Mapping
Building an MCP server usually involves a lot of manual coordination. You already have an API with defined endpoints, but now you have to write a second manifest to explain those same endpoints to an LLM.
- Schema Duplication: You’re taking your existing JSON structures and re-writing them into JSON Schema for the MCP tool definitions. If you update your production API, you now have a second place that needs a manual update to keep the AI from breaking.
- Boilerplate Fatigue: You’re writing handlers to wrap your existing handlers. It’s not complex work, but it is repetitive work that doesn’t actually add new functionality to your product.
2. Managing the SSE Lifecycle
In the last post, we established that SSE is the right choice for production. But in practice, managing those streams is a logistical chore.
- Connection Plumbing: You have to manage the lifecycle of each stream. This means handling heartbeats so the connection doesn’t drop, and making sure that when a model sends a POST request, it’s correctly routed back to that specific user’s event stream.
- Infrastructure Sprawl: Every new MCP server is a new service you have to deploy, monitor, and secure. You’re adding more surface area to your infrastructure that you now have to maintain.
3. The Transformation Layer
LLMs don’t need—and usually shouldn’t get—the raw output of your internal APIs. A 500-line JSON response is a waste of tokens and often confuses the model.
- Custom Pruning: You end up writing logic to strip out the fields the model doesn’t need.
- Data Shaping: You’re essentially building a translator layer whose only job is to take your standard data and make it “AI-ready.”
Why are we building this twice?
By the time you’ve stood up a robust, secure MCP server, you’ve done a lot of engineering, but you haven’t actually changed your data—you’ve just built a new way to access it.
The real question is: if your data is already flowing through a gateway, why aren’t we just letting the gateway handle the translation?
Next Steps
In the final part of this series, we’ll look at how we’re solving these friction points by bringing MCP directly into the gateway layer with Instant MCP for Crate.